여태 개발하면서 무지 많이 써오던 컬랙션들. 성능이나 별다른 고민없이 걍 대충 써왔던 것 같다. "켄트 벡의 구현 패턴"이란 책을 보다 보니 자세한 설명이 있어서 그 동안 알고 있던것과 더불어 정리해 두는 게 조을 것 같다.
1. 인터페이스
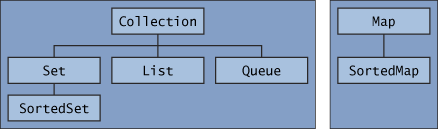
The core collection interfaces.
Queue는 거의 사용하지 않고 책에 없으니까 생략 ^^
- 배열
가장 단순하지만 가장 유연하지 못한 컬렉션.
크기가 고정되어 있고 원소 접근 방법이 용이하면 빠르다.
단순한 연산의 경우 배열은 다른 컬렉션에 비해 시간, 공간 모든 면에서 효율적이다.
일반적으로 배열 접근(element[i])은 ArrayList를 사용했을 때(elements.get(i))에 비해 10배 이상
빠르다고 한다.
대부분의 경우 유연성 문제 때문에 배열보다는 다른 컬렉션을 사용하고, 프로그램의 일부에서 성능이
중요한 경우 배열을 사용하는 것도 고려하는 것이 좋을 듯
- Iterable
기본적인 컬렉션 인터페이스로 순차 열람(iteration)을 지원한다.
어떤 변수를 Iterable로 선언하는 것은 그 변수가 여러 개의 값을 갖고 있음을 뜻할 뿐이다.
실제로 Iterable 인터페이스를 살펴 보면 자바 컬렉션의 모든 인터페이스, 구현 클래스들이 implement
하고 있는 것을 확인할 수 있고 Iterable에 정의된 메소드는 Iterator<T> iterator() 뿐이다.
Iterator를 이용하면 Iterator 인터페이스에서 지원하는 세가지 메소드
(hasNext(), next(), remove())를 사용할 수 있다.
자바 5에서는 암묵적으로 iterator() 메소드를 호출하여
for (Element element : elements) {
......
}
의 형식으로 간편하게 루프를 구성할 수 있게 한다.
실제 프로그램에서는 Iterable 인터페이스를 직접 사용할 일은 없으니 이런게 있다고 정도만 알아두면
될것이다.
- Collection
Iterable을 상속하며, 원소의 추가, 삭제, 검색, 크기 지원 등의 메소드를 추가로 지원한다.
- List
원소의 순서가 정의되어 있으며, 컬렉션상의 위치를 통해 원소에 접근할 수 있다.
따라서 List를 사용하면 컬렉션 상에서의 인덱스를 통해 어떤 원소를 접근 할 수 있다.
원소간의 순서가 중요한 경우, 예를 들어 도착 순서대로 메세지를 처리하는 큐의 경우에는 리스트를
사용해야 한다.
- Set
중복된 원소가 없는 컬렉션
중복원소(상호간 equals()의 결과가 참인 원소)를 허용하니 않는 컬렉션
원소 사이의 순서가 없으므로, 이전 순차 열람할 때의 원소 순서가 다음 순차 열람할 때 보장되지
않는다.
- SortedSet
중복된 원소가 없으며 원소간의 순서가 정해진 컬렉션
컬렉션에 추가된 순서나 명시적인 인덱스 번호에 따라 순서가 정해지는 List와 달리
SortedSet은 Comparator에 의해 순서를 정한다. 명시적인 순서를 제공하지 않는 경우에는
"자연 순서(natural order)"가 사용된다. 예를 들어 문자열은 알파벳 순으로 정렬
아래는 Comparator의 사용예
public Collection<String> getAlphabeticalAuthors() {
Comparator<Author> sorter = new Comparator<Author>() {
public int compare(Author o1, Author o2) {
if (o1.getLastName().equals(o2.getLastName())) {
return o1.getFirstName().compareTo(o2.getFirstName());
return o1.getLastName().compareTo(o2.getLastName());
}
};
SortedSet<Author> results = new TreeSet<Author>(sorter);
for (Book each: getBooks()) {
results.add(each.getAuthor());
}
return results;
}
- Map
키에 의해 원소를 저장하고 접근하는 컬렉션
Map은 List처럼 키를 사용해서 원소를 저장하지만, List가 정수만을 키로 사용할 수 있는 반면
Map은 임의의 객체를 키로사용할 수 있다.
또 Map는 다른 컬렉션 인터페이스와는 형태가 상이하여 다른 컬렉션 인터페이스를 상속하지 않고,
내부적으로 키에 대한 컬렉션과 데이터에 대한 컬렉션의 2개 컬렉션을 유지한다.
컬렉션을 사용할 때는 항상 인터페이스를 선언하여 사용
List<String> list = new ArrayList<String>();
Map<String, String> map = new HashMap<String, String>();
Collection 인터페이스를 사용하면 유연성은 가장 높겠지만 실제 사용한 적은 거의 없는 것 같다.
List, Set, Map이면 ㅇㅋㅂㄹ
2. 구현
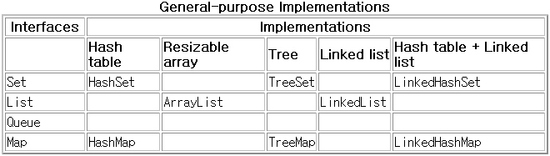
컬렉션에 대해 구현 클래스를 선택하는 것은 주로 성능과 관련이 있다.
위의 표에 소개한 구현 이외에도 무지하게 많은 구현들이 있다. 각 구현체의 특성을 살펴보고 필요한 것을
가져다 사용하면 된다.
일단 가장 단순한 구현을 사용하여 시작하고 추후 경험에 따라 튜닝하는 것이 좋다.
컬렉션중 가장 많이 사용되는 클래스는 ArrayList이며, 그 다음은 HashSet이다.
(이클립스와 JDK에서 ArrayList는 3400번, HashSet은 800번 사용되었다고 한다.)
- Collection 구현
Collection 인터페이스만 구현한 클래스는 없는 듯 하다. 단순한 컬렉션이 필요한 경우
그냥 ArrayList를 사용하자. ArrayList 사용시 성능상 문제되는 부분은 컬렉션의 크기에 비례해서
연산 시간이 커지는 contains(Ojbect)와 이 메소드를 이용하는 다른 메소드(remove() 등)이 있다.
이 때 중복 원소들을 제거해도 상관이 없다면 HashSet으로 교체하면 좋다. 그러나 중복 원소가 이미
없는 경우라면 별 차이가 없을 수도 있다.
- List 구현
ArrayList와 LinkedList
ArrayList는 원소 접근이 빠르고 원소 추가 및 제거가 느린 반면
LinkedList는 원소 접근이 느리지만 원소 추가와 제거는 빠르다.
- Set, SortedSet 구현
HashSet은 가장 빠르지만 원소간의 순서를 보장해주지 않는다.
LinkedHashSet은 원소 간 순서를 보장해 주지만 원소 추가 삭제 시 30% 정도 시간이 더 걸린다.
TreeSet은 Comparator에 따라서 원소를 정렬하지만 원소 추가 삭제 시간이
logn(n은 컬렉션의 크기)에 비례해서 커진다.
- Map 구현
Map 구현은 Set 구현과 비슷한 패턴을 보인다.
HashMap은 가장 빠르고 단순하다.
LinkedHashMap은 컬렉션에 추가된 원소 간의 순서를 보장한다.
TreeMap(SortedMap 의 구현)은 키의 순서에 따라 순차 열람이 가능하지만 원소의 추가 제거 시간이
logn(n은 컬렉션의 크기)에 비례한다.
3. Collections
Collections는 다른 컬렉션 인터페이스에 넣기 적절치 않은 기능들을 모아 놓은 유틸리티 클래스이다.
- 검색
indexOf() 연산에 걸리는 시간은 리스트의 크기에 비례한다. 원소들이 정렬되어 있을 경우
Collections.binarySearch(list, element)를 사용하여 log2n에 비례하는 시간에 검색할 수 있다.
원소가 리스트에 존재하지 않는다면 음수를 반환하고, 리스트가 정렬되어 있지 않다면 결과는 예측불가
- 정렬
reverse(list)는 리스트에 속해 있는 모든 원소 간의 순서를 거꾸로 바꾼다.
shuffle(list)는 순서를 임의로 바꾼다.
sort(list), sort(list, comparator)는 오름차순으로 원소를 정렬한다.
이진 검색과 달리 ArrayList와 LinkedList에서 정렬 수행 성능은 거의 같다. 정렬을 수행할 경우
컬렉션의 원소들이 일단 배열로 복사되어 정렬된 후 다시 본래의 컬렉션으로 복사되기 때문
- 수정 불가능한 컬렉션
신뢰할 수 없는 코드에 컬렉션을 전달하는 경우 Collections.unmodifiableCollection() 메소드를
이용하면 클라이언트가 수정하려 들 경우 예외를 발생시키도록 할 수 있다.
- 단일 원소 컬렉션
하나의 원소를 전달해야 하지만 컬렉션 인터페이스를 사용해야 하는 경우 사용
Set의 경우 Collections.singleton(T o), List와 Map의 경우 singletonList(T o),
singletonMap(K key, V value)를 사용
- 무원소 컬렉션
컬렉션 인터페이스를 사용해야 하지만 전달할 원소가 없는 경우에는 Collections에서 수정할 수 없는
무원소 컬렉션을 생성해서 사용
Collections.emptyList(), emptySet(), emptyMap()
- 동기화 컬렉션
이전 시대의 유물인 Vector와 Hashtable이 ArrayList와 HashMap간의 차이점은 전자가 쓰레드 안전인
반면 후자는 아니라는 것이다.
동기화가 필요없는 경우라면 ArrayList, HashMap을 사용하고 동기화가 필요한 경우
Collections.synchronizedCollection(), Collections.synchronizedList(),
Collections.synchronizedSet(), Collections.synchronizedMap()를 사용하여
ArrayList, HashMap을 래핑하면 멀티 쓰레드 환경에서도 걱정이 사라진다.
[출처] 자바 Collection|작성자 바람의혼